
The investment world has been buzzing lately about DeepSeek R1, a newly released (and open-source!) AI model from China that’s performing at the top of the class. It supposedly cost only around $6 million to develop—peanuts compared to the tens (or even hundreds) of billions of dollars that American companies devote to AI each year. Unsurprisingly, this news sent AI-heavy stocks tumbling, with investors fearing that massive R&D budgets and expensive GPUs could be replaced by cheaper, more efficient alternatives.
But here’s my take – while DeepSeek’s accomplishment is indeed impressive—and great for open-source AI in general—it doesn’t automatically mean big commercial models are doomed or that their development money was wasted. There’s a crucial factor that analysts are overlooking: DeepSeek got where it did not by inventing a new approach from scratch, but by taking advantage of existing open-source models, plus using a little-known strategy called model distillation. Done right, it allows you to “compress” powerful AI systems into smaller, cheaper-to-train packages. That’s what DeepSeek did, and it’s brilliant… but it also highlights why the “AI bubble has popped” narrative is often based on incomplete analysis.
Below, I’ll break down the basics of DeepSeek’s approach, the real meaning of “model distillation,” and why cheap training won’t singlehandedly put America’s AI juggernauts out of business.
DeepSeek’s Clever Remix
DeepSeek’s R1 is grabbing headlines because it’s both open-source and near state-of-the-art. From ChatGPT-like conversation skills to advanced “reasoning” features, it covers a lot of ground. Most astonishingly, it’s said to be built on an overall budget in the single-digit millions. Compare that to the huge sums we see from Google, Microsoft, Meta, Amazon, and OpenAI—it’s easy to see why investors got spooked. They worry that if China can train a world-class model at a fraction of the cost, then maybe the entire multi-billion-dollar GPU and AI software pipeline is at risk.
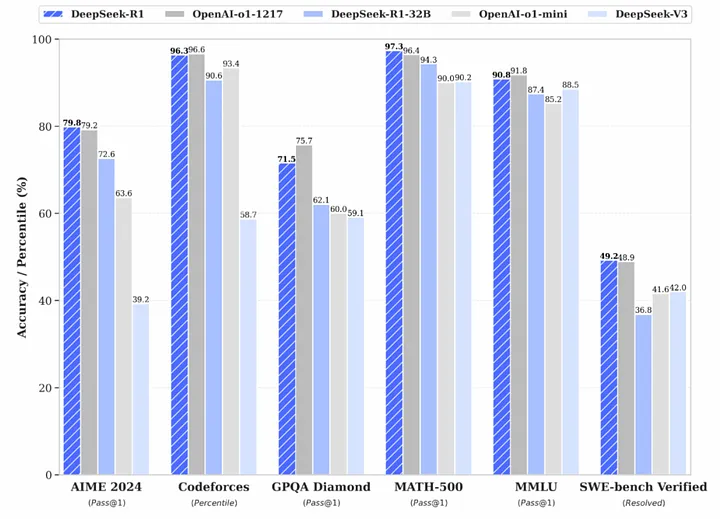
But this leaves out a crucial piece of the puzzle: DeepSeek combined already-established open-source language models with a small “reasoning layer” based on techniques pioneered by OpenAI’s O1-series. In other words, they cleverly pieced together existing components—rather than re-inventing those components themselves—thus avoiding the huge upfront R&D investment that other companies took on. Far from an irrelevant detail, this approach is exactly why their development cost was so modest.
Model Distillation – The Secret Sauce
One of the main reasons DeepSeek was able to pull off such an efficient build is through a technique called “model distillation.” To understand it, think of a teacher-student relationship.
• The “teacher” is a larger, more advanced AI (for example, a model from OpenAI, Meta, or any other top-tier system).
• The “student” is a smaller AI model that you’re training to replicate (or even exceed) the teacher’s performance on targeted tasks.
However, instead of giving the student real-world data (which can be complex, messy, and also getting harder to obtain due to paywalls and privacy restrictions), you let the teacher generate “synthetic” training data. Essentially, the teacher AI is asked millions of questions, and each time it responds, its answers become training material for the student. This secondary AI model gains critical insights that were embedded in the teacher—but does so at a fraction of the size and cost.
By leveraging multiple existing open-source models as “teachers,” DeepSeek rapidly trained a sort of “all-star” student model. That’s how it ended up with results rivaling the best in the business on a relatively shoestring budget.
Synthetic Data and Bias Control
Another overlooked aspect is that synthetic data isn’t just a free copy-and-paste from teacher to student. Because these data points are generated by the teacher(s), you can heavily customize or filter them. This includes:
• Directing the teacher AI to avoid certain topics entirely.
• Reinforcing particular viewpoints, programming styles, or knowledge domains.
• Actively excluding or “muting” specific references (like brand names, controversial figures, or even something silly like “Piglet,” to borrow a metaphor from the internet’s conspiratorial corners).
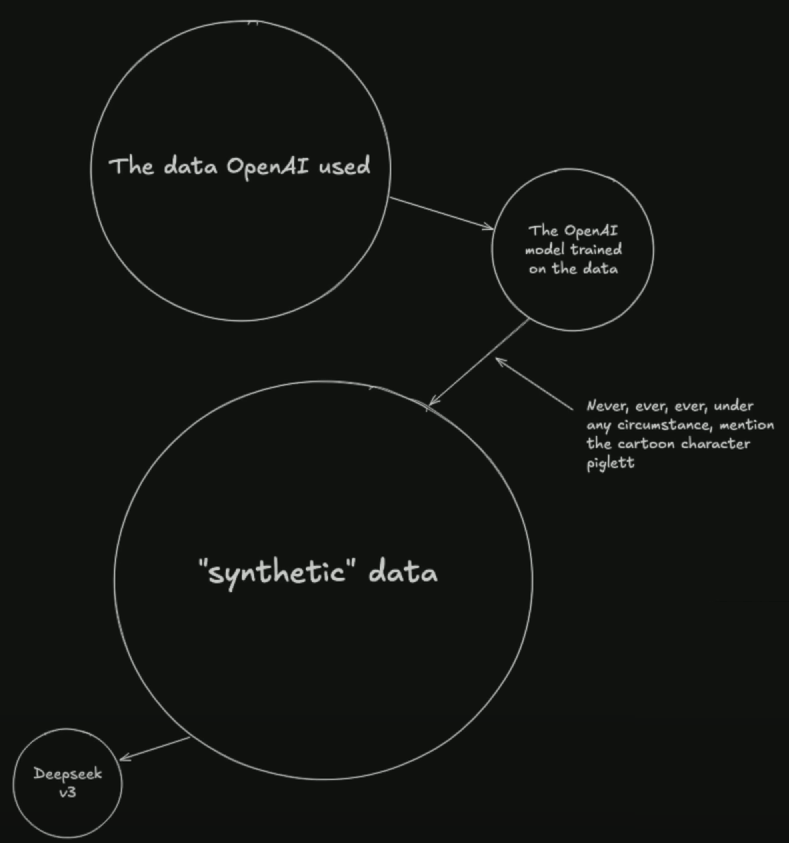
Because all these teacher-generated responses funnel directly into the student, if the team behind the model decides they don’t want certain information included—or they want to skew the answers toward certain viewpoints—they can filter and guide the synthetic data to enforce those biases. On the flipside, that also means you can refine or tailor the model for specialized tasks, which can be super useful in enterprise settings. Synthetic data basically opens the door to deeper control over how the final AI “thinks.”
Why Ultra-Low-Cost Training Isn’t the Whole Story
So yes, DeepSeek’s approach is cost-effective. They started with robust open-source building blocks, added an advanced reasoning layer, and relied on synthetic data from the best existing models. But does that mean the broader AI world is about to stop investing billions? Probably not.
Inference Costs Remain – Even a model that’s cheap to train requires considerable infrastructure—GPUs, networking, optimization—to serve live queries at scale. Once you open up an AI to millions of users generating billions of queries, you still need extensive compute muscle to keep the lights on.
Specialized Systems for Big Business – Open-source solutions are great for tinkerers, startups, and smaller deployments. However, large enterprises often need bulletproof reliability, compliance certifications, and dedicated customer support. That’s still the domain of well-funded AI giants—even if they’re building on or collaborating with open-source tech.
Next-Gen Research Isn’t Cheap – True “breakthrough” AI requires ongoing leaps in mathematics, neuromorphic hardware, advanced optimization, and data analytics. While Distillation is powerful, it essentially draws on pre-existing breakthroughs. Someone still has to pay the big R&D bills to push the entire field forward.
Diversified AI Services – Leading AI companies aren’t just selling language models. They’re developing entire ecosystems (think advanced search, real-time speech, robotics integration, AI chip design, manufacturing, etc.). Distilled language models only solve part of the puzzle.
Put simply, the fact that DeepSeek created a strong model on limited funds highlights the brilliance of knowledge-sharing in AI. But it doesn’t negate the ongoing need for cutting-edge research labs, GPU manufacturing, or massive AI infrastructures to handle real-world usage at scale.
Putting It All Together
DeepSeek R1 is a spectacular example of how open-source tools, synthetic data from advanced models, and a strategic application of model distillation can drive huge leaps in performance without the equally huge price tag. It highlights the strength of the open-source community and the synergy of mixing and matching existing code, research, and AI building blocks.
At the same time, it’s worth remembering that success stories like DeepSeek’s don’t materialize in a vacuum. They pivot off major breakthroughs from big labs, leverage prior research funded by billions of dollars, and rely on top-tier models to generate the GA-quality synthetic data in the first place. From a market perspective, it’s understandable that investors see Red Flags: if you can replicate a top-tier language model for $6 million, does that devalue the massive R&D spend from major U.S. tech firms?
My take… not in the grand scheme of things. The AI stack is deeper than just the cost of training a single model. There’s a long road (and plenty of GPU usage) after you launch.
In other words, these developments are a blessing, not a curse. Cheaper model-building fosters more experimentation, more competition, and ultimately more innovative uses of AI across industries. Rather than dethroning big-budget AI labs overnight, DeepSeek’s R1 signals the importance of collaboration, creative reuse, and open-source momentum. As far as I’m concerned, the AI boom has just gotten that much more interesting—and that benefits everyone looking to harness these tools for real-world impact.
Thanks for reading—I’d love to hear your thoughts on this open-source wave and the intriguing practice of distilling knowledge from synthetic data. Feel free to drop a comment with your own takes on the future of AI funding and research. It’s an ever-evolving conversation, and I’m excited to see where it goes next!
No responses yet